
Developer guide#
Before continuing, ensure you have a working development environment locally or on github codespaces.
Github Codespace#
Github Codespaces allow you to spin up a fully configured dev environment in the cloud in a few minutes. Github provides 60 hours a month of free usage (for a 2-core codespace). While codespaces will automatically pauze after 30 min of idle time, it’s a good idea to shut your codespace down entirely via the management dashboard and to setup spending limits to avoid unexpected charges.
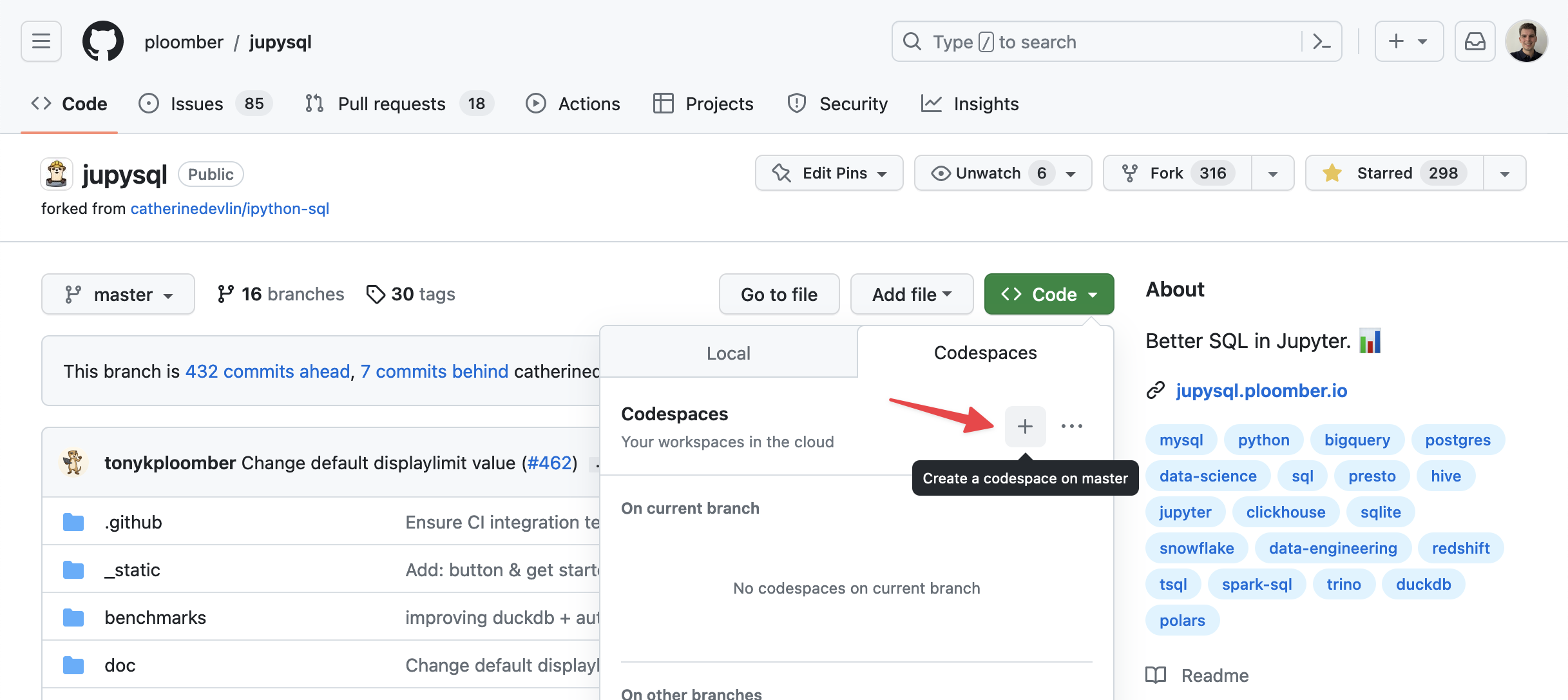 You can launch a new github codespace from the green “Code” button on the JupySQL github repository.
You can launch a new github codespace from the green “Code” button on the JupySQL github repository.
Note that setup will take a few minutes to finish after the codespace becomes available (wait for the postCreateCommand step to finish).
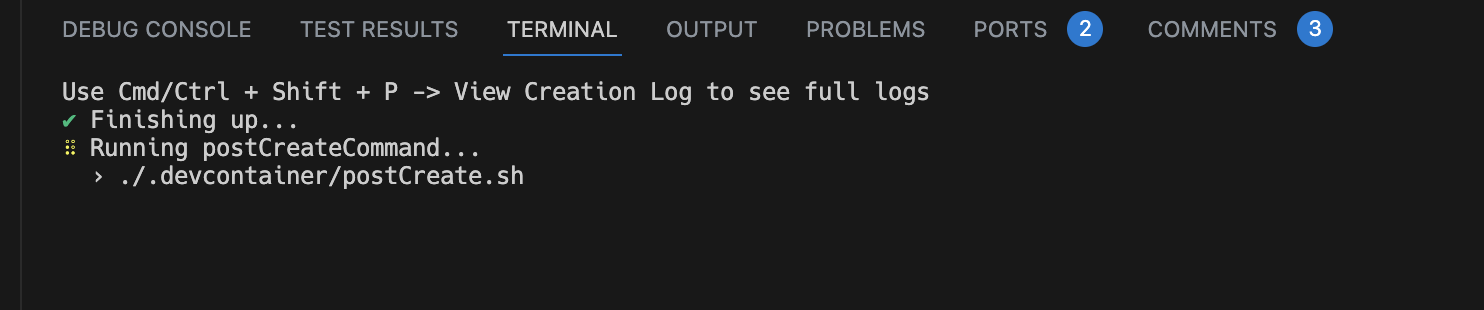
After the codespace has finished setting up, you can run conda activate jupysql to activate the JupySQL Conda environment.
The basics#
JupySQL is a Python library that allows users to run SQL queries (among other things) in IPython and Jupyter via a %sql/%%sql magic:
%load_ext sql
%sql duckdb://
%sql SELECT 42
| 42 |
|---|
| 42 |
However, there is also a Python API. For example, users can create plots using the ggplot module:
from sql.ggplot import ggplot # noqa
So depending on which API is called, the behavior differs. Most notably, when using %sql/%%sql and other magics, Python tracebacks are hidden, since they’re not relevant to the user. For example, if a user tries to query a non-existent table, we won’t show the Python traceback:
%sql SELECT * FROM not_a_table
RuntimeError: If using snippets, you may pass the --with argument explicitly.
For more details please refer: https://jupysql.ploomber.io/en/latest/compose.html#with-argument
Original error message from DB driver:
(duckdb.CatalogException) Catalog Error: Table with name not_a_table does not exist!
Did you mean "temp.information_schema.tables"?
LINE 1: SELECT * FROM not_a_table
^
[SQL: SELECT * FROM not_a_table]
(Background on this error at: https://sqlalche.me/e/20/f405)
If you need help solving this issue, send us a message: https://ploomber.io/community
On the other hand, if they’re using the Python API, we’ll show a full traceback.
Displaying messages#
Important
Use the sql.display module instead of print for showing feedback to the user.
You can use message (contextual information) and message_success (successful operations) to show feedback to the user. Here’s an example:
from sql.display import message, message_success
message("Some information")
message_success("Some operation finished successfully!")
You can use message_html to embed a link in a message and point users to certain sections in our docs. Here’s an example:
from sql.display import message_html, Link
message_html(["Go to our", Link("home", "https://ploomber.io"), "page"])
message_html will detect the running environment and display Go to our home (https://ploomber.io) page message instead if feedback is shown through a terminal.
Throwing errors#
When writing Python libraries, we often throw errors (and display error tracebacks) to let users know that something went wrong. However, JupySQL is an abstraction for executing SQL queries; hence, Python tracebacks a useless to end-users since they expose JupySQL’s internals.
So in most circumstances, we only display an error without a traceback. For example, when calling %sqlplot without arguments, we get an error:
%sqlplot
UsageError: the following arguments are required: plot_name, -t/--table, -c/--column
To implement such behavior, you can use any of the functions defined in sql.exceptions, or implement your own. For example, we have a UsageError that can be raised when users pass incorrect arguments:
from sql import exceptions
raise exceptions.UsageError("something bad happened")
UsageError: something bad happened
There are other exceptions available, if nothing fits in your scenario, you can add new ones.
raise exceptions.ValueError("something bad happened")
ValueError: something bad happened
Important
These errors that hide the traceback should only be used in the %sql/%%sql magic context. For example, in our ggplot API (Python-based), we do not hide tracebacks as users might need them to debug their code
Getting connections#
When adding features to JupySQL magics (%sql/%%sql), you can use the ConnectionManager to get the current open connections.
%load_ext sql
import sqlite3
conn = sqlite3.connect("")
%sql sqlite:// --alias sqlite-sqlalchemy
%sql conn --alias sqlite-dbapi
We can access the current connection using ConnectionManager.current:
from sql.connection import ConnectionManager
conn = ConnectionManager.current
conn
<sql.connection.connection.DBAPIConnection at 0x7f446e38fdc0>
To get all open connections:
ConnectionManager.connections
{'duckdb://': <sql.connection.connection.SQLAlchemyConnection at 0x7f44a79cdd50>,
'sqlite-sqlalchemy': <sql.connection.connection.SQLAlchemyConnection at 0x7f446e1a4a90>,
'sqlite-dbapi': <sql.connection.connection.DBAPIConnection at 0x7f446e38fdc0>}
Using connections#
Connections are either SQLAlchemyConnection or DBAPIConnection object. Both have the same interface, the difference is that the first one is a connection established via SQLAlchemy and DBAPIConnection one is a connection established by an object that follows the Python DB API.
conn_sqlalchemy = ConnectionManager.connections["sqlite-sqlalchemy"]
conn_dbapi = ConnectionManager.connections["sqlite-dbapi"]
raw_execute#
Important
Always use raw_execute for user-submitted queries!
raw_execute allows you to execute a given SQL query in the connection. Unlike execute, raw_execute does not perform any transpilation.
conn_sqlalchemy.raw_execute("CREATE TABLE foo (bar INT);")
conn_sqlalchemy.raw_execute("INSERT INTO foo VALUES (42), (43), (44), (45);")
results = conn_sqlalchemy.raw_execute("SELECT * FROM foo")
print("one: ", results.fetchone())
print("many: ", results.fetchmany(size=1))
print("all: ", results.fetchall())
one: (42,)
many: [(43,)]
all: [(44,), (45,)]
conn_dbapi.raw_execute("CREATE TABLE foo (bar INT);")
conn_dbapi.raw_execute("INSERT INTO foo VALUES (42), (43), (44), (45);")
results = conn_dbapi.raw_execute("SELECT * FROM foo")
print("one: ", results.fetchone())
print("many: ", results.fetchmany(size=1))
print("all: ", results.fetchall())
one: (42,)
many: [(43,)]
all: [(44,), (45,)]
execute#
Important
Only use execute for internal queries! (queries defined in our own codebase, not
queries we receive as strings from the user.)
execute allows you to run a query but it transpiles it so it’s compatible with the target database.
Since each database SQL dialect is slightly different, we cannot write a single SQL query and expect it to work across all databases.
For example, in our plot.py module we have internal SQL queries for generating plots. However, the queries are designed to work with DuckDB and PostgreSQL, for any other databases, we rely on a transpilation process that converts our query into another one compatible with the target database. Note that this process isn’t perfect and it fails often. So whenever you add a new feature ensure that your queries work at least on DuckDB and PostgreSQL, then write integration tests with all the remaining databases and for those that fail, add an xfail mark. Then, we can decide which databases we support for which features.
Note that since execute has a transpilation process, it should only be used for internal queries, and not for user-submitted ones.
results = conn_sqlalchemy.execute("SELECT * FROM foo")
print("one: ", results.fetchone())
print("many: ", results.fetchmany(size=1))
print("all: ", results.fetchall())
one: (42,)
many: [(43,)]
all: [(44,), (45,)]
Writing functions that use connections#
Functions that expect a conn (sometimes named con) input variable should assume the input argument is a connection objects (either SQLAlchemyConnection or DBAPIConnection):
def histogram(payload, table, column, bins, with_=None, conn=None):
pass
Reading snippets#
JupySQL allows users to store snippets:
%sql sqlite-sqlalchemy
%%sql --save fav_number
SELECT * FROM foo WHERE bar = 42
| bar |
|---|
| 42 |
These snippets help them break complex logic in multiple cells and automatically generate CTEs. Now that we saved fav_number we can run SELECT * FROM fav_number, and JupySQL will automatically build the CTE:
%%sql
SELECT * FROM fav_number WHERE bar = 42
| bar |
|---|
| 42 |
In some scenarios, we want to allow users to use existing snippets for certain features. For example, we allow them to define a snippet and then plot the results using %sqlplot. If you’re writing a feature that should support snippets, then you can use the with_ argument in raw_execute and execute:
SQlAlchemyConnection#
results = conn_sqlalchemy.raw_execute("SELECT * FROM fav_number", with_=["fav_number"])
results.fetchall()
[(42,)]
DBAPIConnection#
results = conn_dbapi.raw_execute("SELECT * FROM fav_number", with_=["fav_number"])
results.fetchall()
[(42,)]
dialect#
If you need to know the database dialect, you can access the dialect property in SQLAlchemyConnections:
conn_sqlalchemy.dialect
'sqlite'
Dialect in DBAPIConnection is only implemented for DuckDB, for all others, it currently returns None:
conn_dbapi.dialect is None
True
Testing#
Running unit tests#
Unit tests are executed on each PR; however, you might need to run them locally.
To run all unit tests:
pytest --ignore=src/tests/integration
Some unit tests compare reference images with images produced by the test; such tests might fail depending on your OS, to skip them:
pytest src/tests/ --ignore src/tests/integration --ignore src/tests/test_ggplot.py --ignore src/tests/test_magic_plot.py
To run a specific file:
pytest src/tests/TEST_FILE_NAME.py
Running tests with nox#
We use nox to run the unit and integration tests in the CI. nox automates creating an environment with all the dependencies and then running the tests, while using pytest assumes you already have all dependencies installed in the current environment.
If you want to use nox locally, check out the noxfile.py, and for examples, see the GitHub Actions configuration.
Writing tests for magics (e.g., %sql, %%sql, etc)#
This guide will show you the basics of writing unit tests for JupySQL magics. Magics are commands that begin with % (line magics) and %% (cell magics).
In the unit testing suite, there are a few pytest fixtures that prepare the environment so you can get started:
ip_empty- Empty IPython session (no database connections, no data)ip- IPython session with some sample data and a SQLite connectionTo check the other available fixtures, see the
conftest.pyfiles
So a typical test will look like this:
def test_something(ip):
result = ip.run_cell(
"""%%sql
SELECT * FROM test
"""
)
assert result.success
To see some sample tests, click here.
The ip object is an IPython session that is created like this:
from sql._testing import TestingShell
from sql.magic import SqlMagic
ip_session = TestingShell()
ip_session.register_magics(SqlMagic)
To run some code:
out = ip_session.run_cell("1 + 1")
Out[1]: 2
To test the output:
assert out.result == 2
You can then use pytest to check for errors:
import pytest
with pytest.raises(ZeroDivisionError):
ip_session.run_cell("1 / 0")
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
File <ipython-input-1-bc757c3fda29>:1
----> 1 1 / 0
ZeroDivisionError: division by zero
To check the error message:
with pytest.raises(ZeroDivisionError) as excinfo:
ip_session.run_cell("1 / 0")
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
File <ipython-input-1-bc757c3fda29>:1
----> 1 1 / 0
ZeroDivisionError: division by zero
assert str(excinfo.value) == "division by zero"
Unit testing custom errors#
The internal implementation of sql.exceptions is a workaround due to some IPython limitations; in consequence, you need to test for IPython.error.UsageError when checking if a given code raises any of the errors in sql.exceptions, see test_util.py for examples, and exceptions.py for more details.
from IPython.core.error import UsageError
ip_session.run_cell("from sql.exceptions import MissingPackageError")
# always test for UsageError, even if checking for another error from sql.exceptions!
with pytest.raises(UsageError) as excinfo:
ip_session.run_cell("raise MissingPackageError('something happened')")
UsageError: something happened
Integration tests#
Integration tests check compatibility with different databases. They are executed on each PR; however, you might need to run them locally.
Note
Setting up the development environment for running integration tests locally is challenging given the number of dependencies. If you have problems, message us on Slack.
Ensure you have Docker Desktop before continuing.
To install all dependencies:
# create development environment (you can skip this if you already executed it)
pkgmt setup
# activate environment
conda activate jupysql
# install dependencies
pip install -e '.[integration]'
Tip
Ensure Docker is running before continuing!
To run all integration tests (the tests are pre-configured to start and shut down the required Docker images):
pytest src/tests/integration
Important
If you’re using Apple M chips, the docker container on Oracle Database might fail since it’s only supporting to x86_64 CPU.
You will need to install colima then run colima start --cpu 4 --memory 4 --disk 30 --arch x86_64 before running the integration testing. See more
Send us a message on Slack if any issue happens.
To run some of the tests:
pytest src/tests/integration/test_generic_db_operations.py::test_profile_query
To run tests for a specific database:
pytest src/tests/integration -k duckdb
To see the databases available, check out src/tests/integration/conftest.py
Integration tests with cloud databases#
Currently, we do not run integration tests against cloud databases like Snowflake and Amazon Redshift.
To run Snowflake integration tests locally first set your Snowflake account’s username and password:
export SF_USERNAME="username"
export SF_PASSWORD="password"
Then run the pytest command:
pytest src/tests/integration -k snowflake
Similarly, for Redshift, set the following environment variables:
export REDSHIFT_USERNAME="username"
export REDSHIFT_PASSWORD="password"
export REDSHIFT_HOST="host"
Then run the below command:
pytest src/tests/integration -k redshift
Using Snowflake#
While testing manually with Snowflake, you may run into the below error:
No active warehouse selected in the current session. Select an active warehouse with the 'use warehouse' command.
This occurs when you have connected with a registered account but have no current warehouses. If you have permission to create one, open a worksheet and run:
CREATE WAREHOUSE <wh_name> WITH WAREHOUSE_SIZE = <wh_size>
If you need permissions, have the admin run:
CREATE ROLE create_wh_role;
GRANT ROLE create_wh_role TO USER <your_username>;
GRANT CREATE WAREHOUSE ON ACCOUNT TO ROLE create_wh_role;
Now, open your own worksheet and run:
USE ROLE create_wh_role;
CREATE WAREHOUSE <wh_name> WITH WAREHOUSE_SIZE = <wh_size>
Now, initiate a connection using your new warehouse and run your tests/queries.
SQL transpilation#
As our codebase is expanding, we have noticed that we need to write SQL queries for different database dialects such as MySQL, PostgreSQL, SQLite, and more. Writing and maintaining separate queries for each database can be time-consuming and error-prone.
To address this issue, we can use sqlglot to create a construct that can be compiled across multiple SQL dialects. This clause will allow us to write a single SQL query that can be translated to different database dialects, then use it for calculating the metadata (e.g. metadata used by boxplot)
In this section, we’ll explain how to build generic SQL constructs and provide examples of how it can be used in our codebase. We will also include instructions on how to add support for additional database dialects.
Approach 1 - Provide the general SQL Clause#
We can use SQLGlot to build the general sql expressions.
Then transpile to the sql which is supported by current connected dialect.
Our sql.SQLAlchemyConnection._transpile_query will automatically detect the dialect and transpile the SQL clause.
Example#
# Prepare connection
from sqlglot import select, condition
from sql.connection import SQLAlchemyConnection
from sqlalchemy import create_engine
conn = SQLAlchemyConnection(engine=create_engine(url="sqlite://"))
# Prepare SQL Clause
where = condition("x=1").and_("y=1")
general_sql = select("*").from_("y").where(where).sql()
print("General SQL Clause: ")
print(f"{general_sql}\n")
General SQL Clause:
SELECT * FROM y WHERE x = 1 AND y = 1
# Result
print("Transpiled result: ")
conn._transpile_query(general_sql)
Transpiled result:
'SELECT * FROM y WHERE x = 1 AND y = 1'
Approach 2 - Provide SQL Clause based on specific database#
Sometimes the SQL Clause might be complex, we can also write the SQL Clause based on one specific database and transpile it.
For example, the TO_TIMESTAMP keyword is only defined in duckdb, but we want to also apply this SQL clause to other database.
We may provide sqlglot.parse_one({source_sql_clause}, read={source_database_dialect}).sql() as input sql to _transpile_query()
When current connection is via duckdb#
Prepare connection#
from sql.connection import SQLAlchemyConnection
from sqlalchemy import create_engine
import sqlglot
conn = SQLAlchemyConnection(engine=create_engine(url="duckdb://"))
Prepare SQL clause based on duckdb syntax#
input_sql = sqlglot.parse_one("SELECT TO_TIMESTAMP(1618088028295)", read="duckdb").sql()
Transpiled Result#
conn._transpile_query(input_sql)
'SELECT UNIX_TO_TIME(1618088028295)'
When current connection is via sqlite#
Prepare connection#
from sql.connection import SQLAlchemyConnection
from sqlalchemy import create_engine
conn = SQLAlchemyConnection(engine=create_engine(url="sqlite://"))
Prepare SQL clause based on sqlite#
input_sql = sqlglot.parse_one("SELECT TO_TIMESTAMP(1618088028295)", read="duckdb").sql()
Transpiled Result#
conn._transpile_query(input_sql)
'SELECT UNIX_TO_TIME(1618088028295)'
As you can see, output results are different
From duckdb dialect: 'SELECT TO_TIMESTAMP(1618088028295)'
From sqlite dialect: 'SELECT UNIX_TO_TIME(1618088028295)'