
Mindsdb#
In this guide we’ll show an integration with MindsDB.
We will use Jupysql to run queries on top of MindsDB. Train the model on top of it via SQL. Once the model is ready, we will use sklearn-evaluation to generate plots and evaluate our model.
MindsDB is a powerful machine learning platform that enables users to easily build and deploy predictive models. One of the key features of MindsDB is its integration with Jupysql, which allows users to connect to and query databases from Jupyter notebooks. In this article, we will take a deeper dive into the technical details of this integration, and provide examples of how it can be used in practice. We will explore a customer churn dataset and generate predictions if our customer will churn or not. Once we’re done with that we will evaluate our model and see how easy it is through a single line of code.
The integration between Jupysql and MindsDB is made possible by the use of the sqlite3 library. This library allows for easy communication between the two systems, and enables users to connect to a wide variety of databases and warehouses, including Redshift, Snowflake, Big query, DuckDB, SQLite, MySQL, and PostgreSQL. Once connected, users can run SQL queries directly from the MindsDB environment, making it easy to extract data from databases and use it to train predictive models.
Let’s look at an example of how this integration can be used. Suppose we have a database containing customer churn data, and we want to use this data to train a model that predicts if a customer will churn or not. First, we would need to connect to the database from our Jupyter notebook using the jupysql library. This can be done using the following code:
Pre-requisites#
# Install required packages
%pip install --quiet PyMySQL jupysql sklearn-evaluation --upgrade
Note: you may need to restart the kernel to use updated packages.
from sklearn_evaluation import plot
# Import jupysql Jupyter extension to create SQL cells
%load_ext sql
%config SqlMagic.autocommit=False
The sql extension is already loaded. To reload it, use:
%reload_ext sql
You’d need to make sure your MindsDB is up and reachable for the next stages. You can use either the local or the cloud version.
Note: you will need to adjust the connection string according to the instance you’re trying to connect to (url, user, password). In addition you’d need to load the dataset file into the DB, follow this guide on how to do it.
%sql mysql+pymysql://YOUR_EMAIL:YOUR_PASSWORD@cloud.mindsdb.com:3306
Query#
%sql SHOW TABLES FROM files;
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
2 rows affected.
| Tables_in_files |
|---|
| churn |
| home_rentals |
%%sql
SELECT *
FROM files.churn
LIMIT 5;
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
5 rows affected.
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.3 | 1840.75 | No |
| 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.7 | 151.65 | Yes |
%%sql
CREATE MODEL mindsdb.customer_churn_predictor
FROM files
(SELECT * FROM churn)
PREDICT Churn;
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
0 rows affected.
[]
Training the model#
Training the model have 3 different statuses: Generating, Training, Complete. Since it’s a pretty small dataset it’d take a few minutes to get to the complete status.
Once the status is “complete”, move on to the next section.
Waiting for the below cell to show complete
%%sql
SELECT status
FROM mindsdb.models
WHERE name='customer_churn_predictor';
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
1 rows affected.
| status |
|---|
| complete |
Now that our model is reeady to generate predictions, we can start using it. In the cell below we’ll start by getting a single prediction.
We are classifying if a user will churn, it’s confidence and the explanation based on a few input parameters such as their internet service, if they have phone service, dependents and more.
%%sql
SELECT Churn, Churn_confidence, Churn_explain
FROM mindsdb.customer_churn_predictor
WHERE SeniorCitizen=0
AND Partner='Yes'
AND Dependents='No'
AND tenure=1
AND PhoneService='No'
AND MultipleLines='No phone service'
AND InternetService='DSL';
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
1 rows affected.
| Churn | Churn_confidence | Churn_explain |
|---|---|---|
| Yes | 0.7752808988764045 | {"predicted_value": "Yes", "confidence": 0.7752808988764045, "anomaly": null, "truth": null, "probability_class_No": 0.4756, "probability_class_Yes": 0.5244} |
We can get a batch of multiple entries.
In the cell bellow we’re getting 5 rows (customers) with different parameters such as monthly charges and contract type.
%%sql
SELECT t.customerID, t.Contract, t.MonthlyCharges, m.Churn
FROM files.churn AS t
JOIN mindsdb.customer_churn_predictor AS m
LIMIT 5;
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
5 rows affected.
| customerID | Contract | MonthlyCharges | Churn |
|---|---|---|---|
| 7590-VHVEG | Month-to-month | 29.85 | Yes |
| 5575-GNVDE | One year | 56.95 | No |
| 3668-QPYBK | Month-to-month | 53.85 | Yes |
| 7795-CFOCW | One year | 42.3 | No |
| 9237-HQITU | Month-to-month | 70.7 | Yes |
Classifier evaluation#
Now that our model is ready, we want and should evaluate it. We will query the actual and predicted values from MindsDB to evaluate our model.
Once we have the values we can plot them using sklearn-evaluation.
We will start first by getting all of our customers into a pandas dataframe.
Note: Take a close look on the query below, by saving it into a variable we can compose complex and longer queries.
%%sql result << SELECT t.customerID, t.Contract, t.MonthlyCharges, m.Churn,
t.Churn as actual
FROM files.churn AS t
JOIN mindsdb.customer_churn_predictor AS m;
* mysql+pymysql://ido%40ploomber.io:***@cloud.mindsdb.com:3306
7043 rows affected.
In the cell below, we’re saving the query output into a dataframe.
We then, take the predicted churn values and the actual churn values into seperate variables.
df = result.DataFrame()
y_pred = df.Churn
y_test = df.actual
Plotting#
Now that we have the values needed to evaluate our model, we can plot it into a confusion matrix:
plot.ConfusionMatrix.from_raw_data(y_test, y_pred, normalize=False)
<sklearn_evaluation.plot.classification.ConfusionMatrix at 0x1083dd480>
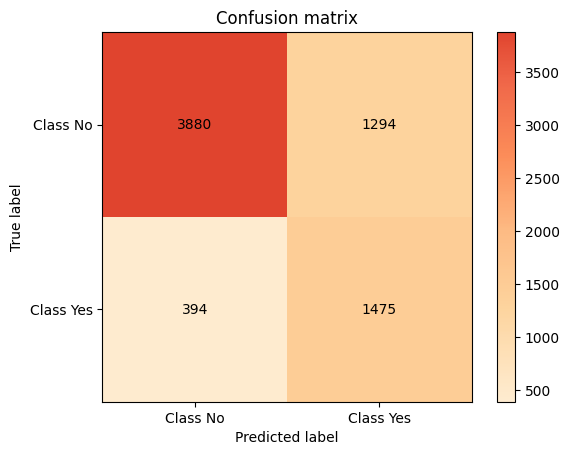
Additionally we can generate a classification report for our model and compare it with other different models or previous iterations.
target_names = ["No churn", "churn"]
report = plot.ClassificationReport.from_raw_data(
y_test, y_pred, target_names=target_names
)
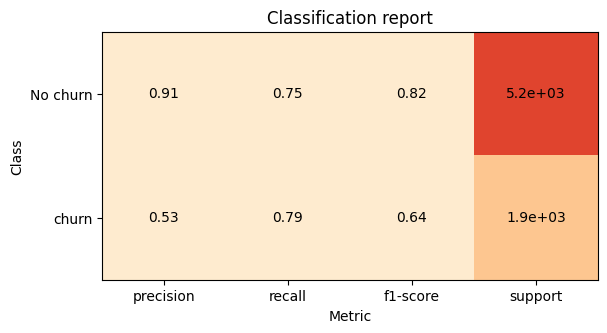
Conclusion#
In conclusion, the integration between Jupysql and MindsDB is a powerful tool for building and deploying predictive models. It allows easy data extraction and manipulation, and makes it simple to deploy models into production. This makes it a valuable tool for data scientists, machine learning engineers, and anyone looking to build predictive models. With this integration, the process of data extraction, cleaning, modeling, and deploying can all be done in one place: your Jupyter notebook. MindsDB on the other hand is making it a more efficient and streamlined process reducing the need for compute.