
Microsoft SQL Server#
In this tutorial, we’ll see how to query Microsoft SQL Server from Jupyter. Optionally, you can spin up a testing server.
Tip
If you encounter issues, feel free to join our community and we’ll be happy to help!
Pre-requisites#
The first step is to install the ODBC driver for SQL Server.
For example, if you’re on a Mac, you can install the driver with brew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
brew tap microsoft/mssql-release https://github.com/Microsoft/homebrew-mssql-release
brew update
HOMEBREW_ACCEPT_EULA=Y brew install msodbcsql18 mssql-tools18
Start Microsoft SQL Server instance#
If you don’t have a SQL Server running or you want to spin up one for testing, you can do it with the official Docker image.
Important
If you’re on a Mac with Apple Silicon (e.g., M1 processor), ensure you’re running the latest Docker Desktop version. More info here.
To start the server:
%%bash
docker run -e "ACCEPT_EULA=Y" \
-e "MSSQL_SA_PASSWORD=MyPassword!" \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
00721df70ea8d5f91c792a84f28f4e0fc6c0ff53f1f4d04cb6911a3a4714deba
Important
Ensure you set a strong password, otherwise the container will shut down silently!
Ensure that your container is running (run the command a few seconds after running the previous one to ensure it dind’t shut down silently):
%%bash
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
If you have issues with the previous command, you can try with SQL Edge:
%%bash
docker run -e "ACCEPT_EULA=1" -e "MSSQL_SA_PASSWORD=MyPassword!" \
-e "MSSQL_PID=Developer" -e "MSSQL_USER=sa" \
-p 1433:1433 -d --name=sql mcr.microsoft.com/azure-sql-edge
fabfc30490a17dc0a48313c35289218ff563070b11622bc43f07e82080b2a201
Ensure the server is running (wait for a few seconds before running it):
%%bash
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fabfc30490a1 mcr.microsoft.com/azure-sql-edge "/opt/mssql/bin/perm…" 5 seconds ago Up 4 seconds 1401/tcp, 0.0.0.0:1433->1433/tcp sql
Installing pyodbc#
pyodbc will allow us to connect to SQL Server. If you’re on macOS or Linux, you need to install unixODBC. Note that when installing the ODBC driver on macOS using brew, unixODBC is also installed.
Install pyodbc with:
pip install pyodbc
Note
If you’re on a Mac with Apple Silicon (e.g., M1 processor), you might encounter issues, if so, try thi:
pip install pyodbc==4.0.34
Verify a successful installation with:
import pyodbc
Verify that pyodbc is able to findn the SQL Server driver:
pyodbc.drivers()
['ODBC Driver 18 for SQL Server']
Tip
If the driver doesn’t appear, uninstalling pyodbc and re-installing it again might fix the problem.
If you’re on a Mac with Apple Silicon, ensure you installed pyodbc with pip, since conda might lead to issues.
Starting the connection#
To start the connection, execute the following, change the values to match your SQL Server’s configurationo:
from sqlalchemy import create_engine
from sqlalchemy.engine import URL
connection_url = URL.create(
"mssql+pyodbc",
username="sa",
password="MyPassword!",
host="localhost",
port=1433,
database="master",
query={
"driver": "ODBC Driver 18 for SQL Server",
"Encrypt": "yes",
"TrustServerCertificate": "yes",
},
)
engine = create_engine(connection_url)
Note
If using pytds, the autocommit feature is disabled since it’s not compatible with JupySQL.
Install, load the Jupyter extension and start the connection:
%pip install jupysql --quiet
Note: you may need to restart the kernel to use updated packages.
%load_ext sql
%sql engine
Note
If you see the following error:
InterfaceError: (pyodbc.InterfaceError) ('IM002', '[IM002] [unixODBC][Driver Manager]Data source name not found and no default driver specified (0) (SQLDriverConnect)')
(Background on this error at: https://sqlalche.me/e/14/rvf5)
It might be that you’re missing the SQL Server ODBC driver or that pyodbc cannot find it.
Load sample data#
Let’s upload some sample data:
import pandas as pd
df = pd.read_parquet(
"https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet"
)
df.shape
(1369769, 19)
df.sample(100_000).to_sql(
name="taxi", con=engine, chunksize=100_000, if_exists="replace"
)
56
Query#
Query the new table:
%%sql
select COUNT(*) FROM taxi
List the tables in the database:
%sqlcmd tables
| Name |
|---|
| MSreplication_options |
| spt_fallback_db |
| spt_fallback_dev |
| spt_fallback_usg |
| spt_monitor |
| taxi |
List columns in the taxi table:
%sqlcmd columns --table taxi
| name | type | nullable | default | autoincrement | comment |
|---|---|---|---|---|---|
| index | BIGINT | True | None | False | None |
| VendorID | BIGINT | True | None | False | None |
| tpep_pickup_datetime | DATETIME | True | None | False | None |
| tpep_dropoff_datetime | DATETIME | True | None | False | None |
| passenger_count | FLOAT | True | None | False | None |
| trip_distance | FLOAT | True | None | False | None |
| RatecodeID | FLOAT | True | None | False | None |
| store_and_fwd_flag | VARCHAR COLLATE "SQL_Latin1_General_CP1_CI_AS" | True | None | False | None |
| PULocationID | BIGINT | True | None | False | None |
| DOLocationID | BIGINT | True | None | False | None |
| payment_type | BIGINT | True | None | False | None |
| fare_amount | FLOAT | True | None | False | None |
| extra | FLOAT | True | None | False | None |
| mta_tax | FLOAT | True | None | False | None |
| tip_amount | FLOAT | True | None | False | None |
| tolls_amount | FLOAT | True | None | False | None |
| improvement_surcharge | FLOAT | True | None | False | None |
| total_amount | FLOAT | True | None | False | None |
| congestion_surcharge | FLOAT | True | None | False | None |
| airport_fee | FLOAT | True | None | False | None |
Parametrize queries#
threshold = 10
%%sql
SELECT COUNT(*) FROM taxi
WHERE trip_distance < {{threshold}}
threshold = 0.5
%%sql
SELECT COUNT(*) FROM taxi
WHERE trip_distance < {{threshold}}
CTEs#
You can break down queries into multiple cells, JupySQL will build a CTE for you:
%%sql --save many_passengers --no-execute
SELECT *
FROM taxi
WHERE passenger_count > 3
-- remove top 1% outliers for better visualization
AND trip_distance < 18.93
%%sql --save trip_stats --with many_passengers
SELECT MIN(trip_distance), AVG(trip_distance), MAX(trip_distance)
FROM many_passengers
| _1 | _2 | |
|---|---|---|
| 0.0 | 2.5377720207253898 | 18.83 |
ResultSet : to convert to pandas, call .DataFrame() or to polars, call .PolarsDataFrame()This is what JupySQL executes:
query = %sqlcmd snippets trip_stats
print(query)
WITH many_passengers AS (
SELECT *
FROM taxi
WHERE passenger_count > 3
-- remove top 1% outliers for better visualization
AND trip_distance < 18.93)
SELECT MIN(trip_distance), AVG(trip_distance), MAX(trip_distance)
FROM many_passengers
Plotting#
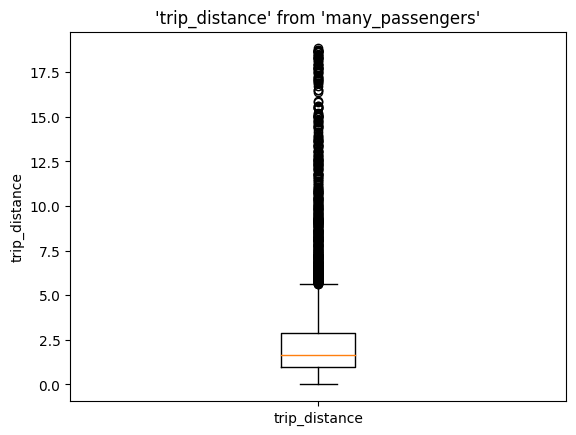
Boxplot#
%sqlplot boxplot --table many_passengers --column trip_distance
<Axes: title={'center': "'trip_distance' from 'many_passengers'"}, ylabel='trip_distance'>
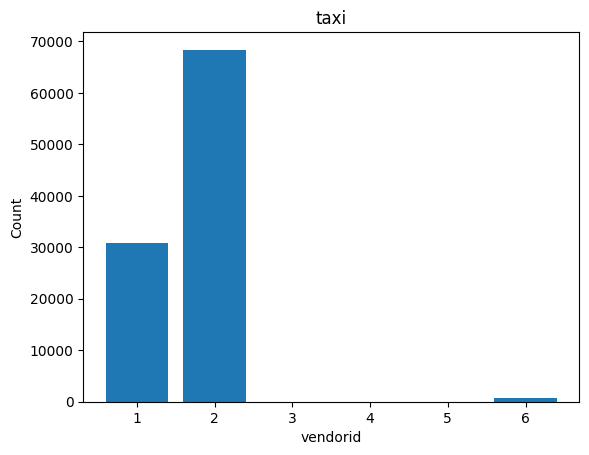
Bar#
%sqlplot bar --table taxi --column vendorid
<Axes: title={'center': 'taxi'}, xlabel='vendorid', ylabel='Count'>
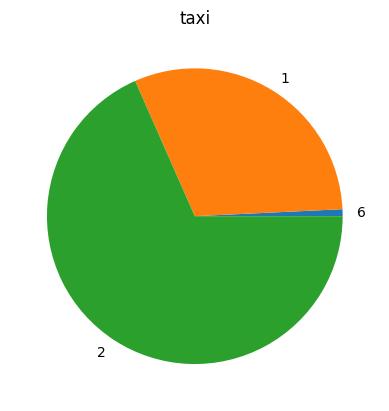
Pie#
%sqlplot pie --table taxi --column vendorid
<Axes: title={'center': 'taxi'}>
Clean up#
%%bash
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fabfc30490a1 mcr.microsoft.com/azure-sql-edge "/opt/mssql/bin/perm…" 7 minutes ago Up 7 minutes 1401/tcp, 0.0.0.0:1433->1433/tcp sql
%%bash
docker container stop sql
sql
%%bash
docker container rm sql
sql
%%bash
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES