
Trino#
This tutorial will show you how to get a Trino (f.k.a PrestoSQL) instance up and running locally to test JupySQL. You can run this in a Jupyter notebook.
Pre-requisites#
To run this tutorial, you need to install following Python packages:
%pip install jupysql trino pandas pyarrow --quiet
Note: you may need to restart the kernel to use updated packages.
You also need a Trino connector. Here is the supported connector. You can install it with:
%pip install sqlalchemy-trino --quiet
Note: you may need to restart the kernel to use updated packages.
Start Trino instance#
We fetch the official image, create a new database, and user (this will take a few seconds).
%%bash
docker run -p 8080:8080 --name trino -d trinodb/trino
cba8365556d3f35dd56cfd06747276ef1c7b7661eb4268b74e665d8d4d44a7e7
Our database is running, let’s load some data!
Load sample data#
Now, let’s fetch some sample data. We’ll be using the NYC taxi dataset:
import pandas as pd
df = pd.read_parquet(
"https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet"
)
df.shape
(1369769, 19)
Trino has maximum query text length of 1000000. Therefore, writing the whole NYC taxi dataset (~1.4M rows) will throw errors. A workaround is to increase the http-server.max-request-size configuration parameter to Trino’s maximum allowed characters of 1,000,000,000 in the Trino server configuration file (config.properties). We’ll write a subset of the data instead:
df = df.head(1000)
Trino uses a schema named “default” to store tables. Therefore, schema='default' is required in the connection string.
from sqlalchemy import create_engine
engine = create_engine(
"trino://user@localhost:8080/memory", connect_args={"user": "user"}
)
df.to_sql(
con=engine,
name="taxi",
schema="default",
method="multi",
index=False,
)
engine.dispose()
Query#
Now, let’s start JupySQL, authenticate, and query the data!
%load_ext sql
%sql trino://user@localhost:8080/memory
Important
If the cell above fails, you might have some missing packages. Message us on Slack and we’ll help you!
List the tables in the database:
%sqlcmd tables --schema default
| Name |
|---|
| taxi |
List columns in the taxi table:
%sqlcmd columns --table taxi --schema default
| name | type | nullable | default |
|---|---|---|---|
| vendorid | BIGINT | True | None |
| tpep_pickup_datetime | TIMESTAMP | True | None |
| tpep_dropoff_datetime | TIMESTAMP | True | None |
| passenger_count | DOUBLE | True | None |
| trip_distance | DOUBLE | True | None |
| ratecodeid | DOUBLE | True | None |
| store_and_fwd_flag | VARCHAR | True | None |
| pulocationid | BIGINT | True | None |
| dolocationid | BIGINT | True | None |
| payment_type | BIGINT | True | None |
| fare_amount | DOUBLE | True | None |
| extra | DOUBLE | True | None |
| mta_tax | DOUBLE | True | None |
| tip_amount | DOUBLE | True | None |
| tolls_amount | DOUBLE | True | None |
| improvement_surcharge | DOUBLE | True | None |
| total_amount | DOUBLE | True | None |
| congestion_surcharge | DOUBLE | True | None |
| airport_fee | DOUBLE | True | None |
Query our data:
%%sql
SELECT COUNT(*) FROM default.taxi
| _col0 |
|---|
| 1000 |
Parameterize queries#
threshold = 10
%%sql
SELECT COUNT(*) FROM default.taxi
WHERE trip_distance < {{threshold}}
| _col0 |
|---|
| 949 |
threshold = 0.5
%%sql
SELECT COUNT(*) FROM default.taxi
WHERE trip_distance < {{threshold}}
| _col0 |
|---|
| 64 |
CTEs#
%%sql --save many_passengers --no-execute
SELECT *
FROM default.taxi
WHERE passenger_count > 3
-- remove top 1% outliers for better visualization
AND trip_distance < 18.93
%%sql --save trip_stats --with many_passengers
SELECT MIN(trip_distance), AVG(trip_distance), MAX(trip_distance)
FROM many_passengers
| _col0 | _col1 | _col2 |
|---|---|---|
| 0.25 | 3.16470588235294 | 11.15 |
This is what JupySQL executes:
query = %sqlcmd snippets trip_stats
print(query)
WITH many_passengers AS (
SELECT *
FROM default.taxi
WHERE passenger_count > 3
AND trip_distance < 18.93)
SELECT MIN(trip_distance), AVG(trip_distance), MAX(trip_distance)
FROM many_passengers
Plotting#
The %sqlplot magic command currently does not directly support the --schema option for specifying the schema name. To work around this, you can specify the schema in the SQL query itself.
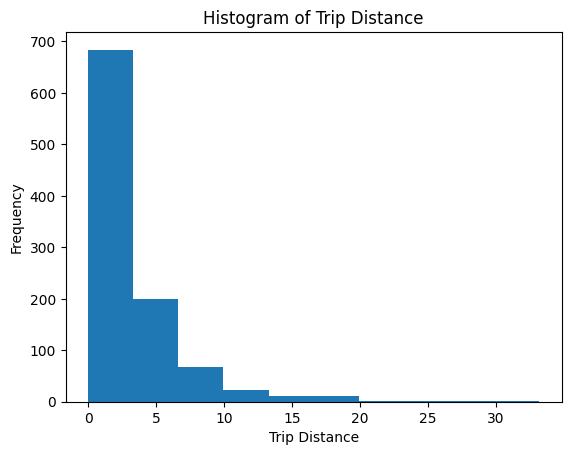
result = %sql SELECT trip_distance FROM default.taxi
import matplotlib.pyplot as plt
data = result.DataFrame()
plt.hist(data["trip_distance"])
plt.xlabel("Trip Distance")
plt.ylabel("Frequency")
plt.title("Histogram of Trip Distance")
plt.show()
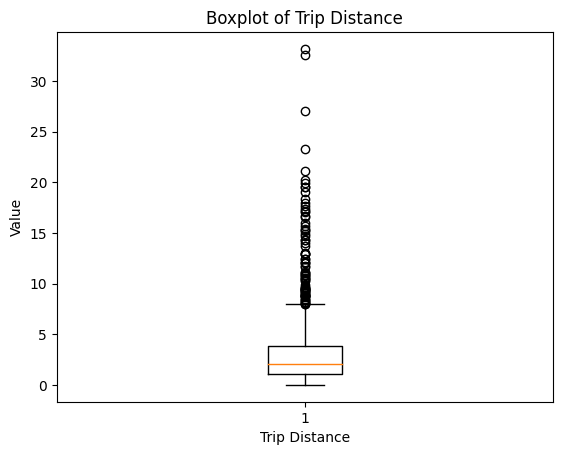
result = %sql SELECT trip_distance FROM default.taxi
import matplotlib.pyplot as plt
data = result.DataFrame()
plt.boxplot(data["trip_distance"])
plt.xlabel("Trip Distance")
plt.ylabel("Value")
plt.title("Boxplot of Trip Distance")
plt.show()
Persist#
result = %sql SELECT * FROM default.taxi WHERE passenger_count > 3
df = result.DataFrame()
We need to pass --no-index since index creation is not supported in Trino DB.
%sql --persist default.df --no-index
%sql SELECT * FROM default.df LIMIT 5
| vendorid | tpep_pickup_datetime | tpep_dropoff_datetime | passenger_count | trip_distance | ratecodeid | store_and_fwd_flag | pulocationid | dolocationid | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | congestion_surcharge | airport_fee |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-01-01 00:31:06 | 2021-01-01 00:38:52 | 5.0 | 1.7 | 1.0 | N | 142 | 50 | 1 | 8.0 | 0.5 | 0.5 | 2.36 | 0.0 | 0.3 | 14.16 | 2.5 | None |
| 2 | 2021-01-01 00:42:11 | 2021-01-01 00:44:24 | 5.0 | 0.81 | 1.0 | N | 50 | 142 | 2 | 4.5 | 0.5 | 0.5 | 0.0 | 0.0 | 0.3 | 8.3 | 2.5 | None |
| 2 | 2021-01-01 00:31:06 | 2021-01-01 00:38:52 | 5.0 | 1.7 | 1.0 | N | 142 | 50 | 1 | 8.0 | 0.5 | 0.5 | 2.36 | 0.0 | 0.3 | 14.16 | 2.5 | None |
| 2 | 2021-01-01 00:42:11 | 2021-01-01 00:44:24 | 5.0 | 0.81 | 1.0 | N | 50 | 142 | 2 | 4.5 | 0.5 | 0.5 | 0.0 | 0.0 | 0.3 | 8.3 | 2.5 | None |
| 2 | 2021-01-01 00:34:37 | 2021-01-01 00:47:22 | 4.0 | 3.15 | 1.0 | N | 238 | 162 | 1 | 12.5 | 0.5 | 0.5 | 2.0 | 0.0 | 0.3 | 18.3 | 2.5 | None |
Clean up#
To stop and remove the container:
! docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cba8365556d3 trinodb/trino "/usr/lib/trino/bin/…" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:8080->8080/tcp trino
%%capture out
! docker container ls --filter ancestor=trinodb/trino --quiet
container_id = out.stdout.strip()
print(f"Container id: {container_id}")
Container id: cba8365556d3
! docker container stop {container_id}
cba8365556d3
! docker container rm {container_id}
cba8365556d3
! docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES